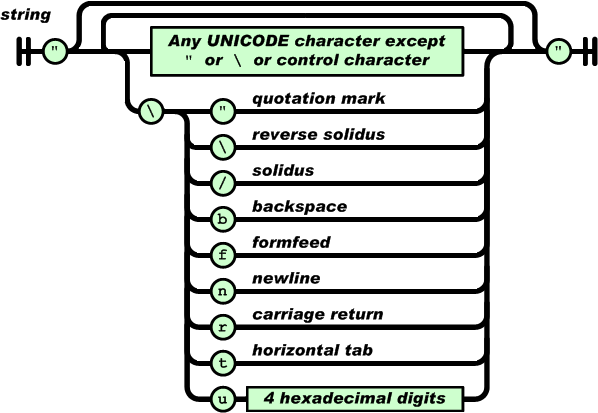
Seeing errors like these? java.io.FileNotFoundException at android.content.res.AssetManager.openAsset(Native Method) at android.content.res.AssetManager.open(AssetManager.java:315) at android.content.res.AssetManager.open(AssetManager.java:289) The problem is that Eclipse isn’t finding your file, because you may not be using AssetManager to retrieve plain-text files from the assets folder. Here’s how to fix…